When the back-flip skills of the Boston Dynamics humanoid robot unveiled, it surprised the global audience.

With such complicated movements, it goes without saying that robots in the real world, even in simulators, are very difficult to learn.
Now, a new method recently studied by the University of California at Berkeley and the University of British Columbia can teach robots living in simulators to imitate humans and learn complex skills such as martial arts, parkour, and acrobatics.
Backflip maneuvers kick something, easy to get ~
(Besides, there will be many "bots" mentioned below, which basically all live in simulators)
Making robots, animations, and game characters move smoothly and flexibly is a goal pursued by researchers in the fields of computer graphics, reinforcement learning, robotics, and so on.
Different methods have their own strengths and of course they are short.
Using the reinforcement learning method to teach robots (agents in the simulator) can learn a wide variety of actions, meticulous to get things, and bold to run can be done, but also can set a clear purpose for the robot. However, there is always some shame or surprise play.
Motion capture technology allows robots to behave exactly like real people, naturally fluent and unobtrusive. However, it is impossible to count on the use of living sciences. Each movement and each form of robot needs to be trained individually.
Berkeley's scientists took the leadership of these two fields and created a new method DeepMimic. This method not only has the versatility of the deep learning model, it can cover more types of actions and robot forms, and the natural fluency of actions can also be comparable to motion capture.
With this new method, how does the robot learn new moves?
In simple terms, learning by watching motion clips, human motion capture data is a good learning material. Show the robot a sample of the action, such as the side flip in the figure below, and the right side is an example sample for the robot to learn.

The scientists involved in the study decomposed the demonstration action into a sequence of q^0, q^1, ..., q^T, and q^T represents the target action of the robot at time step t. The goal of this robot learning is to eliminate the gap between the actual action qT and the target action q^T as much as possible.
The robot industriously practises practice exercises until its actions are no longer shameful, and the flexibility and simulation can be comparable to the demo videos, as shown on the left side of the figure above.
Instructing this exercise process is such a reward function:
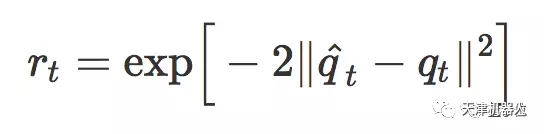
In addition to flipping, robots taught in this way can learn Chinese and Western dances, Nanquan North Legs, running and playing and even squid strikes:



What does it mean to capture a sample of a perfect motion and copy it again? Of course, this research does not stop at imitating. DeepMimic allows the robot to use it after learning to learn and use it.
For example, when a robot learns to throw a ball, it can perform a task that is not included in the demo sample. We can specify a target in the simulator to let it vote:

Trained robots can also grow much less like demo samples. For example, using the backflip sample from the front, you can train a robot that simulates Boston Power Altas:

Even robots that are not humanoid can be trained with humanoid samples. For example, this Tyrannosaurus Rex is a walk with a humanoid sample. In the paper's home page, they also showed more examples, even lions and dragons.
Twinkle System Technology Co Ltd , https://www.pickingbylight.com